Classification 分类问题
问题描述: Given a training set 训练集:{(x_1,y_1),(x_2,y_2),(x_3,y_3)}, Produce a classifier 分类器 (function) that maps any unknown object x_i to its class label y_i.
算法 决策树 Decision Trees K-近邻算法 KNN 神经网络 Neural Networks 支持向量机 SVM
应用 客户流失预测Churn Prediction:是/否会流失 医学诊断Medical Diagnosis:有/没有病,恶性/良性
决策边界 (Classification Decision Boundary) 将每个item量化映射到多维空间中的一个点,然后对点进行分类。 边界可以是:一条或者多条曲线,曲面 
过拟合 (Overfitting) 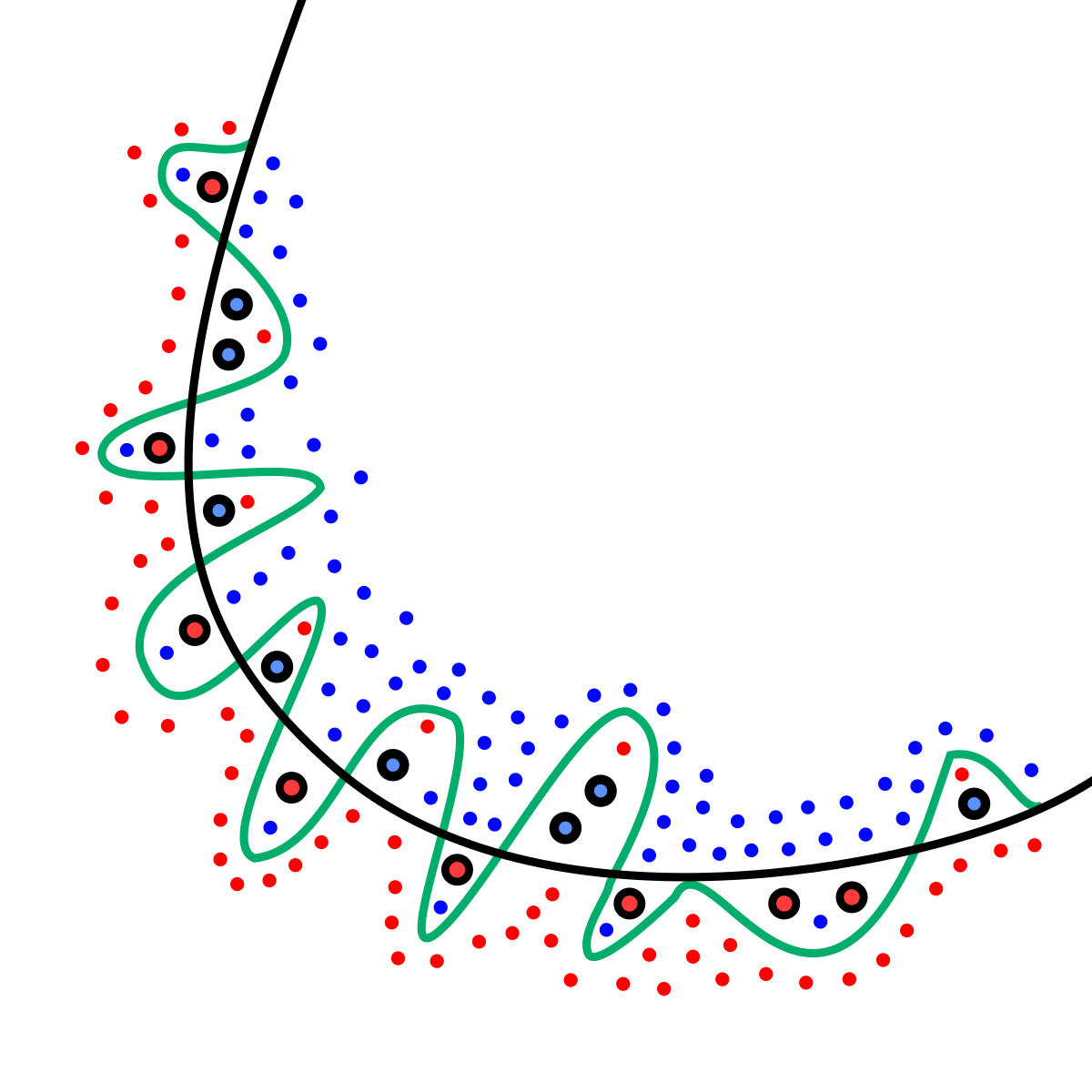
交叉验证 (Cross-validation) 验证的时候 要求 测试集Test Set 是 训练集 以外的集合
混淆矩阵 (Confusion Matrix) 用来统计正确预测的次数,矩阵中罗列出真实结果和预测结果组成的所有情况, True Positive 和True Negative的情况是预测吻合事实。 False Positive 和False Negative是预测与事实不吻合的情况 1 准确率 Accuracy = (TP+TN)/(P+N) 2 TPR=TP/(TP+FN) 正解是P的人里蒙对了几成 3 TNR = TN/(TN+FP) 正解是N的人里蒙对了几成 eg:2分类问题(Positive or Negative) 
ROC曲线 (Receiver Operating Characteristic) 1 横坐标:FP 预测结果是男人,实际是女人 2 纵坐标:TP 预测结果是男人,实际是男人 Eg:身高-->男女 (h >1 m 预测男人)全预测成男人 FPR=1,TPR=1 (h >2.5 m 预测男人)全预测成女人TPR=0,FPR=0 
AUC (Area Under Curve) 评价ROC曲线的好坏,是ROC曲线下方面积,越大越好,最大值是1 Random guess是y=x,AUC=0.5
代价敏感的学习 (cost-sensitive learning) 宁肯错杀一千,不可放过一个。 2分问题中会有两种分类错误,但是代价是不一样的 医学诊断(有病->没病,没病->有病) 邮件分类(重要->垃圾,垃圾->重要)
提升度分析 (Lift Analysis) 对每个item打分,将容易成功的item提到前面,提升模型的精确度 eg:做营销 将容易成功的客户排到前面,只打10个电话,成功了4个,假设排序之前只能成功1个, 那么提升度 就是4 = 0.4/0.1
转载请注明来源 https://tianweiye.github.io